By João Peterson on 23 Mar 2026 | 01:00 .
Categories | Gnucash | Algorithms | Data
Tempo de leitura: #
Visualizações: #
Sumário
- Sumário
- Introdução
- Como o GnuCash faz
- Tokenização e pesos
- Aplicando o Teorema de Bayes
- Expandindo para múltiplos tokens
- Simplificando a fórmula
- Modelagem em banco relacional
- A query completa com Laplace Smoothing
- Conclusão
- Referências
Introdução
Uma leitura interessante da noite: bayesian statistics para associação entre strings e labels, e como fazer isso em escala em um banco relacional.
Tudo começou investigando como o GnuCash fazia para associar a descrição de uma transação bancária a uma conta contábil. O resultado é um classificador de texto probabilístico elegante e surpreendentemente simples.
Como o GnuCash faz
O GnuCash possui um Import Map Editor que mostra a relação entre strings de entrada (descrições de transações) e as contas contábeis mapeadas, junto com a contagem de uso de cada associação.
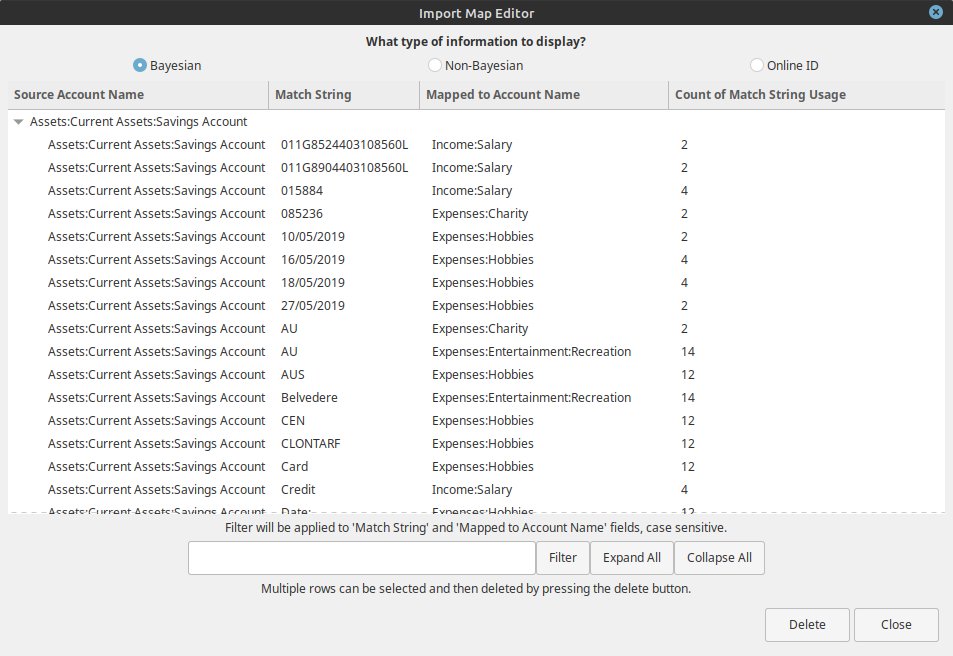
Basicamente, o GnuCash tokeniza a string de entrada (a descrição da transação) e salva a relação entre cada token e uma label (conta contábil), guardando a quantidade de vezes que aquele token foi associado àquela conta.
Tokenização e pesos
Quando avaliamos a relação entre um texto e uma label novamente, basta tokenizar o texto, pegar todas as labels associadas aos tokens e somar os pesos de cada label. Assim temos um score por label.
Então aplicamos um peso em cada label pela quantidade de vezes que um token aparece nelas. A ideia central é:
- Se um token aparece várias vezes na mesma label, ele é muito relevante para identificar aquela label.
- Se um token aparece espalhado em muitas labels diferentes, ele perde relevância — quanto mais distribuído, menos poder discriminativo ele tem para distinguir uma label das outras. Ele se torna quase “ruído”, pois não ajuda a diferenciar nenhuma categoria específica.
Isso nos dá a probabilidade final para cada label.
Aplicando o Teorema de Bayes
Na realidade, o que descrevemos acima é uma simplificação intuitiva. Formalizando com o Teorema de Bayes, temos:
\[P(label \mid token) = \frac{P(label) \times P(token \mid label)}{P(token)}\]Ou seja, a chance de uma label ser a correta para um token é igual à probabilidade da label (prior), multiplicada pela chance do token aparecer dado aquela label (likelihood), dividido pela probabilidade total do token (evidence).
Expandindo para múltiplos tokens
Mas queremos classificar textos inteiros, não tokens individuais. Como a probabilidade de cada label e token individual são apenas frequências dentro do conjunto, basta calcular a chance de todos os tokens pertencerem a uma label — que é o produto das chances de cada token para a mesma label:
\[score(Entertainment) = \frac{P(label) \times \prod P(t_i \mid Entertainment)}{P(t_1 \cap t_2 \cap t_3)}\] \[score(Utilities) = \frac{P(label) \times \prod P(t_i \mid Utilities)}{P(t_1 \cap t_2 \cap t_3)}\] \[score(Shopping) = \frac{P(label) \times \prod P(t_i \mid Shopping)}{P(t_1 \cap t_2 \cap t_3)}\]Simplificando a fórmula
Como os tokens são os mesmos em cada avaliação por label, o \(P(token)\) no denominador pode ser removido, pois é comum entre todas as labels. Assim temos que a probabilidade é proporcional ao numerador:
\[P(label \mid tokens) \propto P(label) \times \prod_i P(t_i \mid label)\]A probabilidade de cada label ser a correta para um texto é proporcional à probabilidade da label multiplicada pela probabilidade de cada token dado a label.
Modelagem em banco relacional
Na prática, podemos modelar isso com três tabelas: tokens, labels e token_labels. Fazemos upsert de tokens e labels, e sempre incrementamos um contador em token_labels para cada associação observada.
CREATE TABLE tokens (
id INTEGER PRIMARY KEY,
token TEXT NOT NULL UNIQUE
);
CREATE TABLE labels (
id INTEGER PRIMARY KEY,
label TEXT NOT NULL UNIQUE
);
CREATE TABLE token_labels (
token_id INTEGER NOT NULL REFERENCES tokens(id),
label_id INTEGER NOT NULL REFERENCES labels(id),
frequency INTEGER NOT NULL DEFAULT 0,
PRIMARY KEY (token_id, label_id)
);
A query completa com Laplace Smoothing
Com essa modelagem, podemos fazer uma query que calcula a contagem total de frequência de todos os tokens e suas labels, ajustando o score de cada token_label pelo número total daquele token, agrupado por label e multiplicado pela probabilidade de cada label.
Um detalhe importante: precisamos de Laplace Smoothing para evitar edge cases onde nem todo token está associado a uma label, o que jogaria o produto inteiro para zero (já que qualquer fator zero zera a multiplicação). O smoothing adiciona uma pequena constante ao numerador e ajusta o denominador, evitando probabilidades zero.
Como trabalhamos com produtos de probabilidades (números menores que 1), na prática usamos a soma dos logaritmos ao invés do produto direto — isso evita underflow numérico e é matematicamente equivalente:
\[\log(score) = \ln(P(label)) + \sum_i \ln(P(t_i \mid label))\]A query completa com CTEs fica assim:
WITH vocab_size AS (
SELECT COUNT(DISTINCT token_id) as V FROM token_labels
),
label_totals AS (
SELECT label_id, SUM(frequency) as total
FROM token_labels
GROUP BY label_id
),
grand_total AS (
SELECT SUM(frequency) as total FROM token_labels
),
prior AS (
SELECT lt.label_id, lt.total * 1.0 / gt.total as p_label
FROM label_totals lt, grand_total gt
),
likelihoods AS (
SELECT
tl.label_id,
-- Laplace smoothed likelihood
SUM(LN((tl.frequency + 1.0) / (lt.total + v.V))) as log_likelihood
FROM token_labels tl
JOIN tokens t ON tl.token_id = t.id
JOIN label_totals lt ON tl.label_id = lt.label_id
, vocab_size v
WHERE t.token IN ('NETFLIX', 'PAYMENT')
GROUP BY tl.label_id
)
SELECT
l.label,
-- log(prior) + sum of log likelihoods
LN(p.p_label) + li.log_likelihood as score
FROM likelihoods li
JOIN prior p ON li.label_id = p.label_id
JOIN labels l ON li.label_id = l.id
ORDER BY score DESC
LIMIT 1;
A CTE vocab_size calcula o tamanho do vocabulário (total de tokens distintos), usado no Laplace Smoothing. As CTEs label_totals e grand_total calculam os totais para as probabilidades. O prior dá a probabilidade de cada label, e likelihoods calcula a soma dos log-likelihoods com smoothing para os tokens de entrada. No final, somamos o log do prior com os log-likelihoods e ordenamos pelo maior score.
Conclusão
É bem complexo mas também muito legal ver como funciona um classificador de texto probabilístico. O GnuCash usa essa abordagem para associar transações bancárias a contas contábeis de forma automática, e o mesmo princípio pode ser aplicado em qualquer problema de classificação de texto onde temos dados históricos de associação.
O melhor de tudo é que tudo roda dentro de um banco relacional com SQL puro — sem precisar de bibliotecas externas de machine learning.