By João Peterson on 17 Oct 2023 | 23:40 .
Categories | Linux | The web | Reverse Engineering
Tempo de leitura: #
Visualizações: #
Introdução
Olá leitores, nesse post queria compartilhar com vocês o processo de engenharia reversa do LinkedIn para poder implementar um simples botão de download a mais na página via uma extensão do chrome, espero que gostem.
Sumário
- Introdução
- Sumário
- Proposta
- Scrapping do pdf
- iframe e cors
- Window messaging
- Stack tracing
- Finalmente, o pdf
- Chegando ao fim
- Extensão publicada
Proposta
A ideia era basicamente fazer isso:
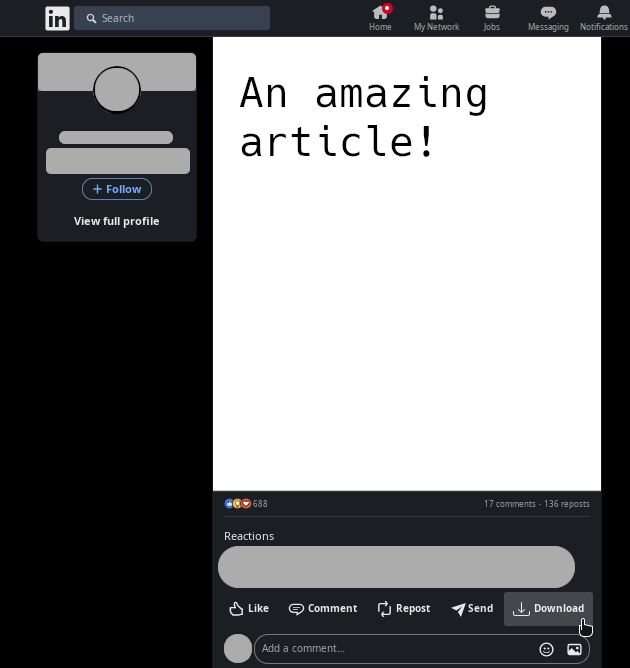
Colocar um botão de download junto ao botões de media social capaz de realizar o download do conteúdo, especialmente de conteúdo do tipo artigo, que eu queria que fosse baixado como um pdf, já que temos bastante coisas bacana no lado tech do LinkedIn, bastante infográficos e cheat sheets.
A forma como pensei em fazer seria utilizando uma extensão que injeta se esse elemento de botão na página e de alguma forma conseguisse acesso a origem da imagem, para baixa lá, mais fácil pensar do que fazer, gostaria de compartilhar com vocês a minha primeira ideia, acessar o elemento.
Scrapping do pdf
A ideia inicial era somente usar ver se tínhamos um src no elemento do artigo, e baixar a partir dai, não existia.
Explorando mais com o inspect do chrome, vi que na verdade o artigo era um carousel de imagens, e cada imagem tinha fonte, pensei, usar um seletor para pegar o elemento ul e fazer um loop for para baixar cada imagem dos li > img e depois juntar todas em um único pdf, e adivinhe só, não foi simples assim, pois o document.querySelector funcionava no console mas não na extensão, por que? Tenho vergonha de dizer mas for por que entre os elementos do artigo e a página do LinkedIn existia um iframe.
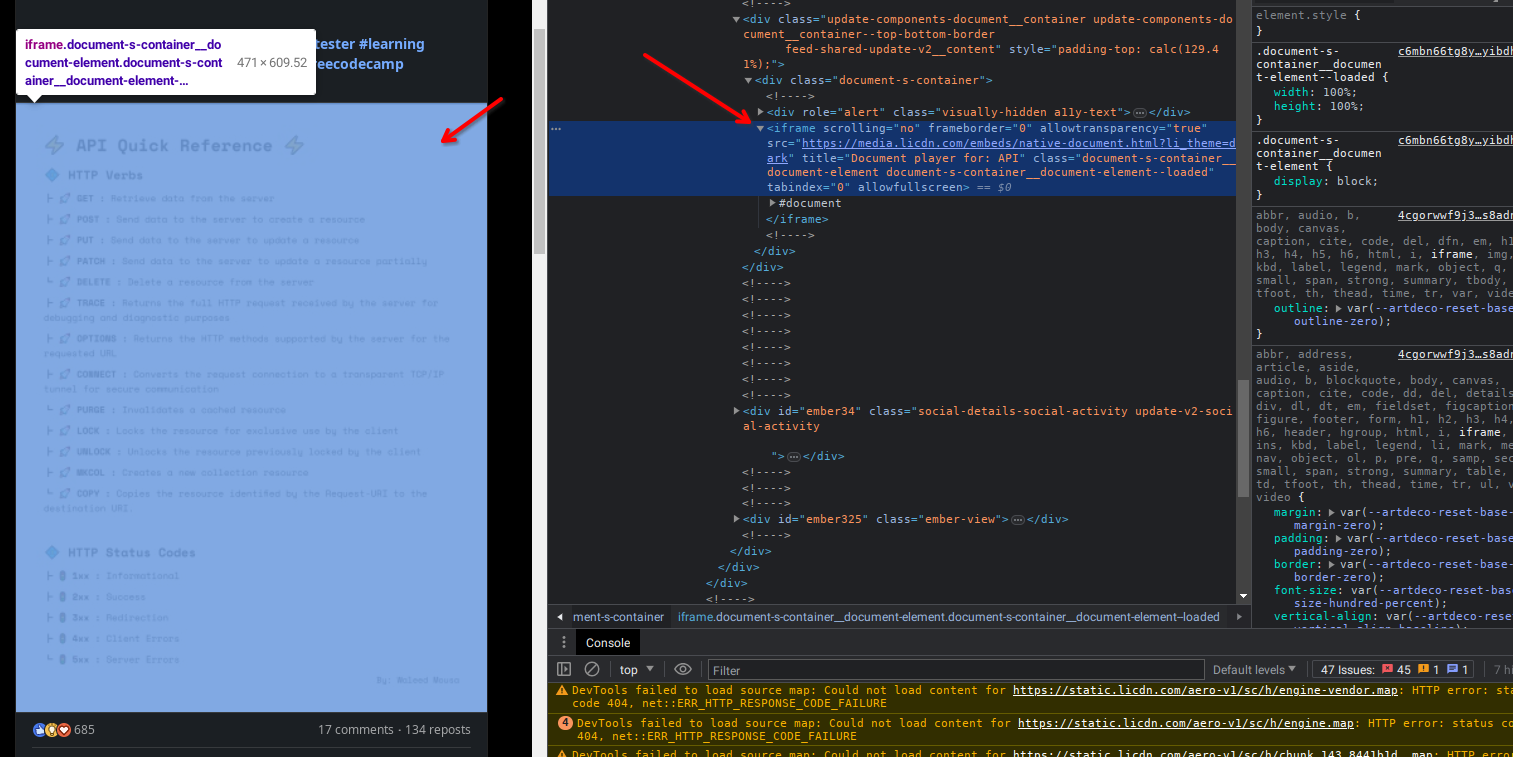
iframe e cors
O iframe é uma janela embutida capaz de exibir outro HTML, e nesse caso estava sendo usado como container para o visualizador de artigo. Pensei, tudo bem, só selecionar o iframe e fazer o query selector no elemento, senão fosse pelo fato do iframe do LinkedIn estar um página sobre o domínio linkedin e a origem do iframe no domínio da cdn do LinkedIn, media.lincdn, poderia ser possível, mas pesquisando soluções e mais sobre iframes, vi que existem limitações sobre interações com iframe de domínio diferentes do host, devido ao fato de ser isso poder ser usado para cross site scripting, XSS.
Ou seja, é uma rua sem fim tentar acessar os elementos do iframe pela DOM do host.
A nova ideia agora era acessar a origem do elemento de forma externa e recuperar os elementos a partir daí. Mas olhando para a fonte fo iframe vemos algo estranho:
https://media.licdn.com/embeds/native-document.html?li_theme=dark
Não há argumentos, query, ou qualquer indicação de qual fonte utilizar, e quando abrimos a origem de forma manual vemos:
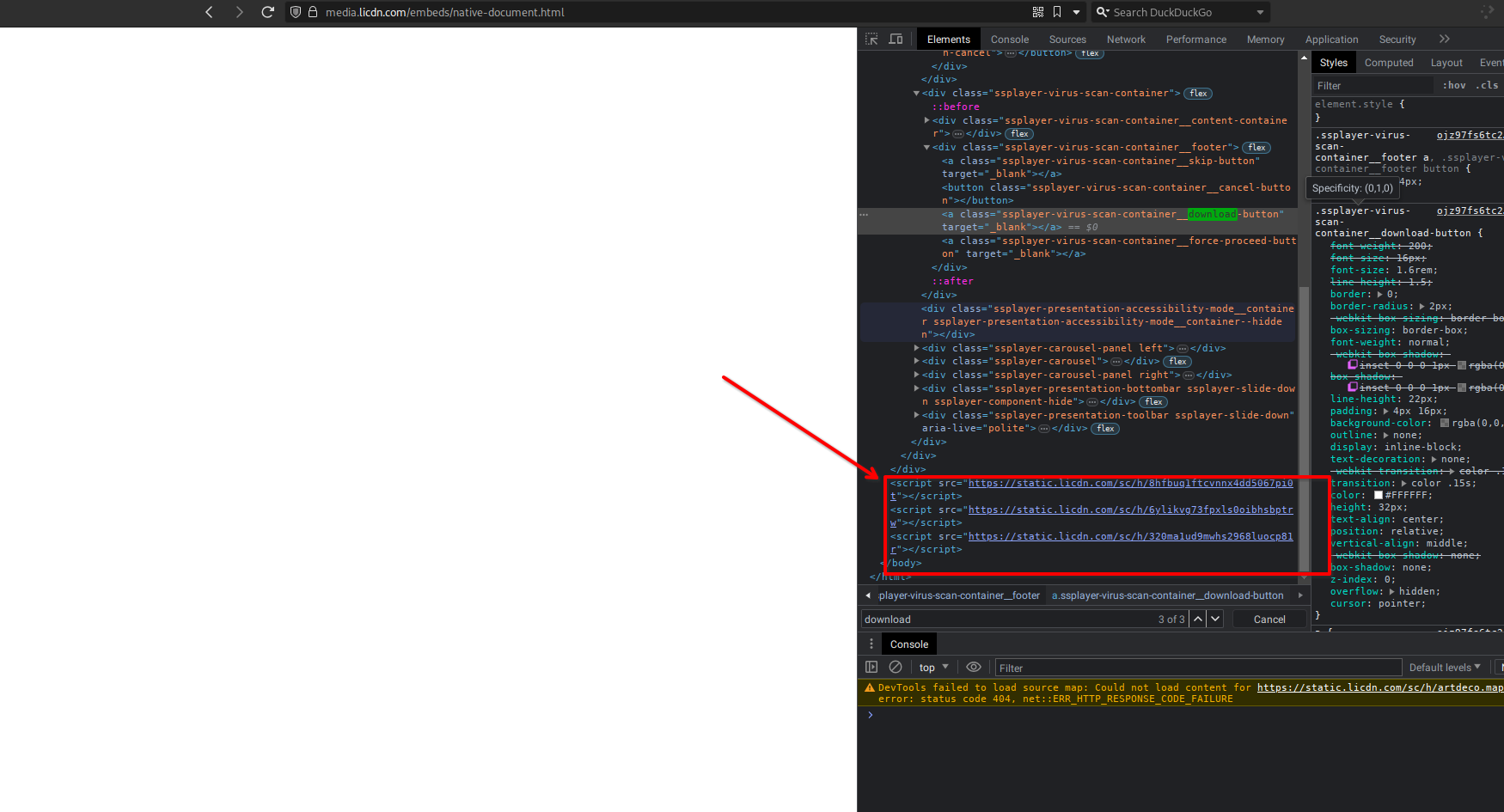
Uma página em branco, como?????
Nesse ponto eu estava perdendo as esperanças de criar um simples botão de download, mas pesquisando mais ainda sobre iframes, vi que há mecanismos de como um host pode ‘conversar’ com uma origem de um iframe, fui investigar um pouco mais…
Window messaging
Existe possibilidade de realizar comunicação entre Windows caso você tenha acesso a ambos os servidores, como imagino ser o caso do LinkedIn e suas cdn’s. Então o plano era achar nos scripts os métodos usado, como postMessage(), e bada bim, bada bum, no script https://static.licdn.com/sc/h/6ylikvg73fpxls0oibhsbptrw, temos confirmação que o LinkedIn utiliza iframes para implementar o container do leitor de artigo, sendo este, um documento vazio que é populado de forma dinâmica pelo host através de window messaging.
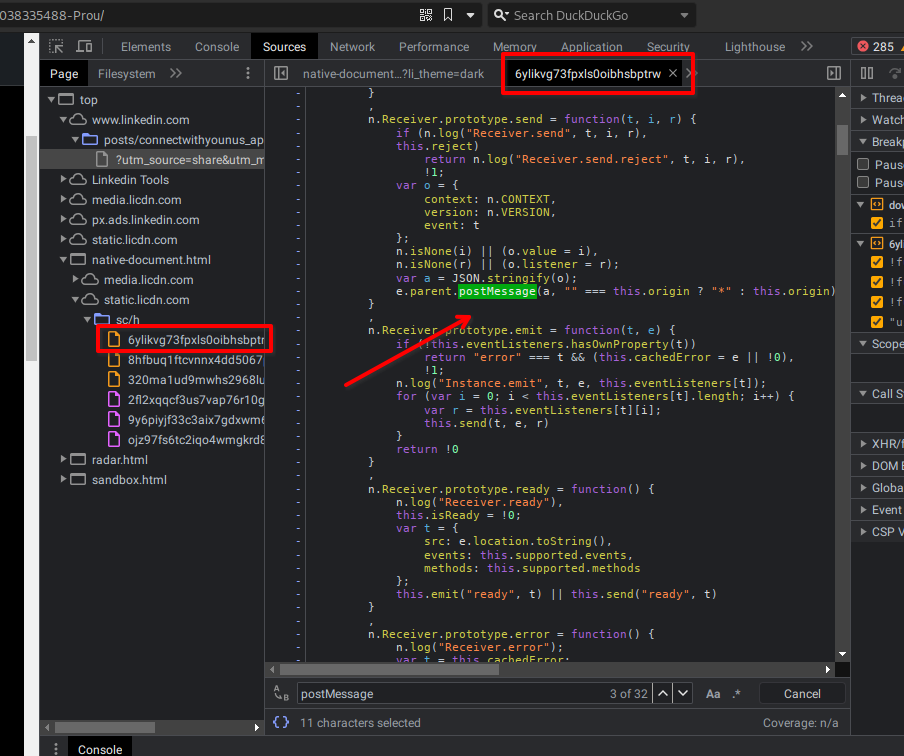
Bom, nono plano, vamos descobrir com as informações do documento chegam na página. Existe dentro do leitor um botão de download bem escondido, que contém a url para baixar o arquivo já em formato pdf, amazing, então agora é questão de saber como essa url foi para lá.
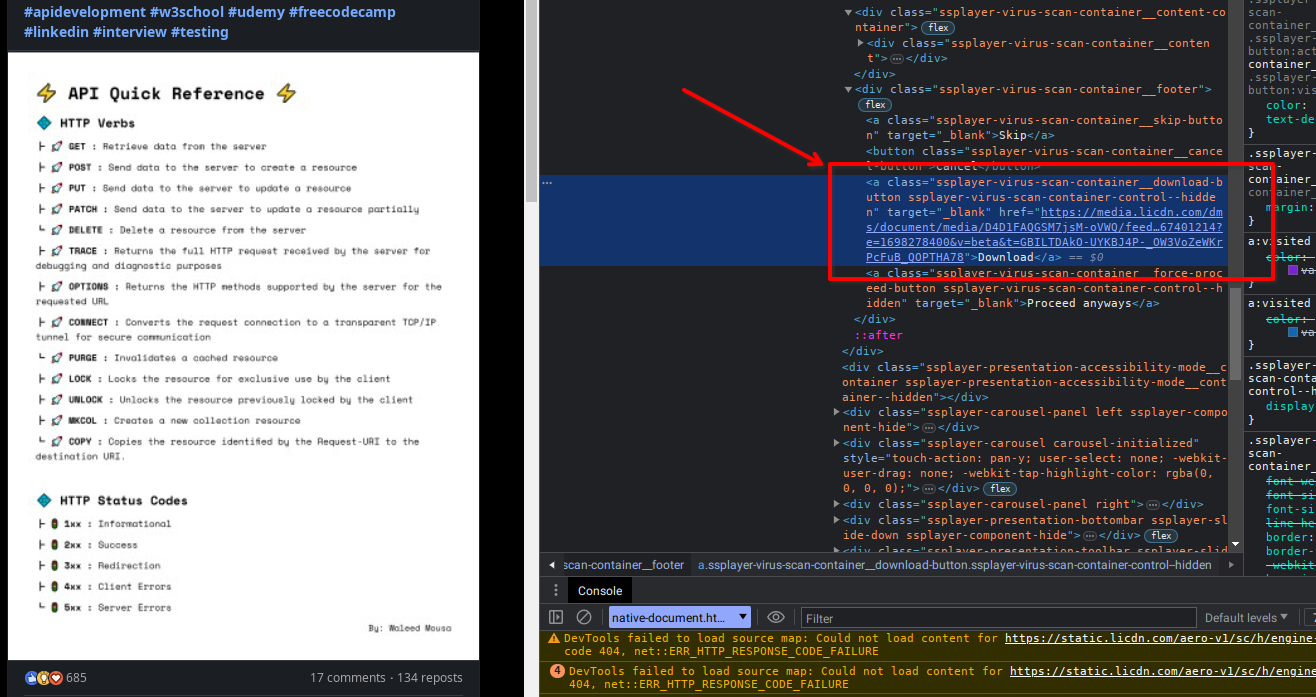
Claramente foi usado um selector ou outro meio de identificar o elemento para injetar a origem do pdf, e olha só, temo um find:

Seguindo os nomes e procurando achamos também, onde se injeta o href do download.
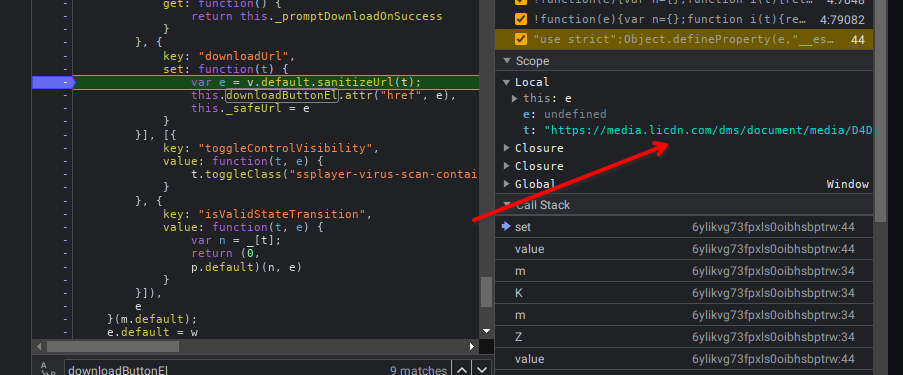
Agora a idéia era ir indo pela call stack do script e ver quem chamava quem e como essa url chegava aqui.
Stack tracing
Aqui temos a stack trace detalha feita na mão:
- Stack trace 1
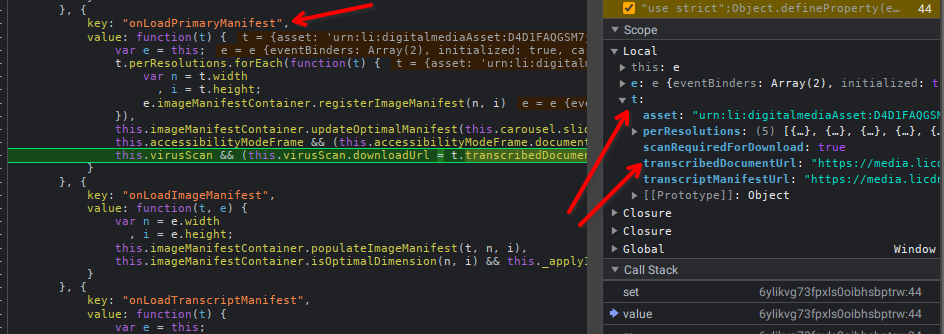
- Stack trace 2
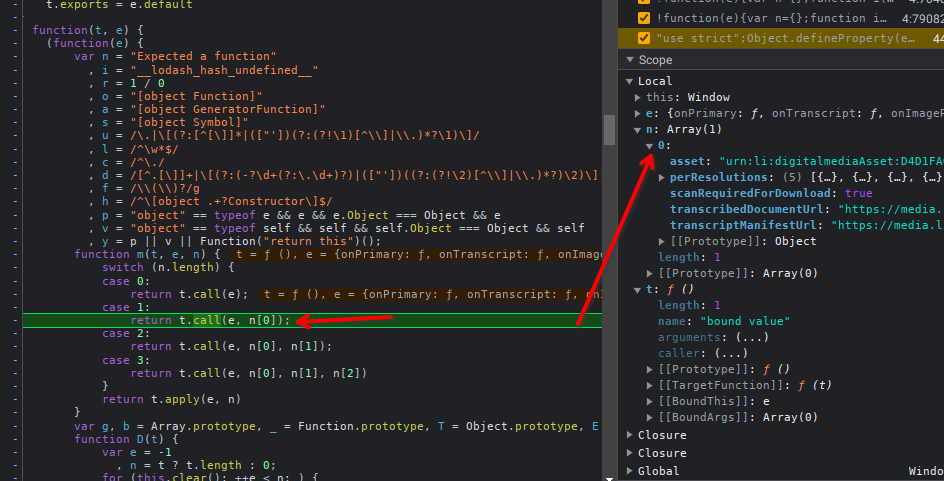
- Stack trace 3
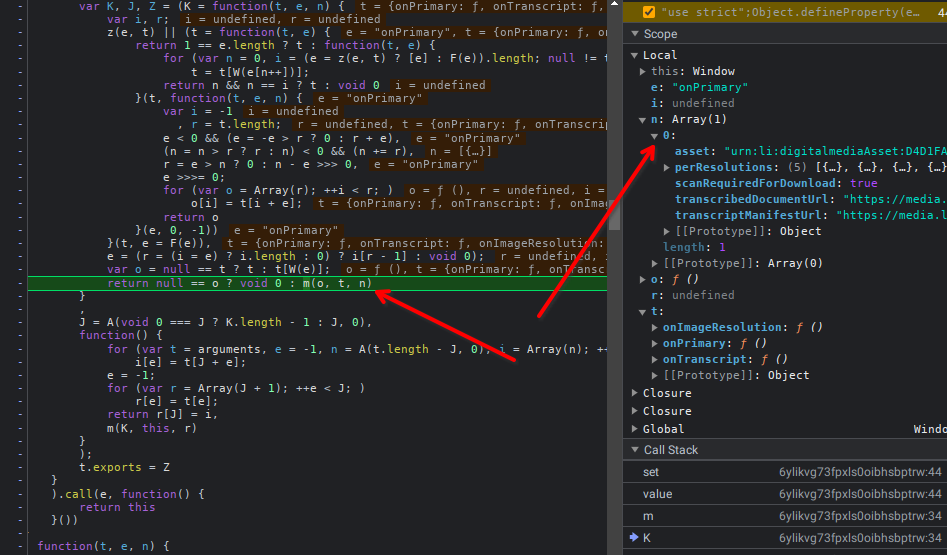
- Stack trace 4
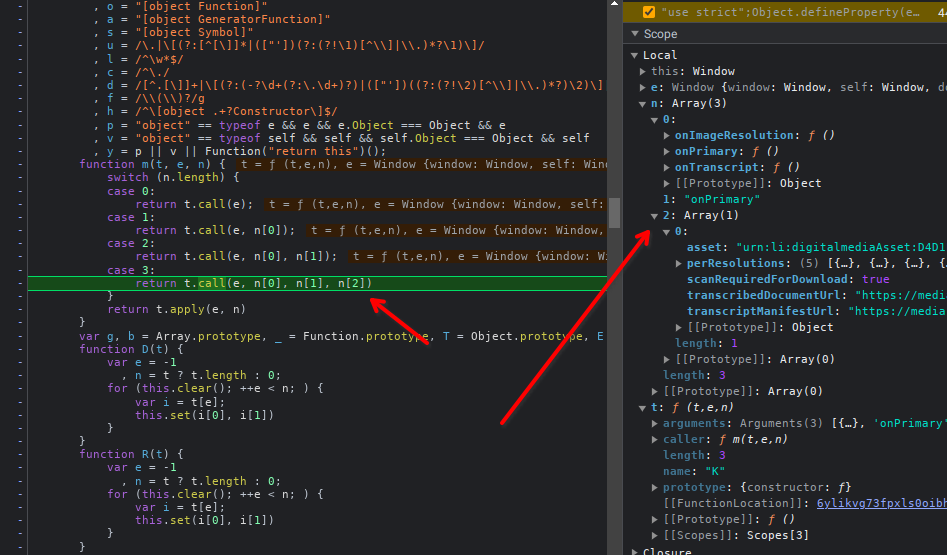
- Stack trace 5
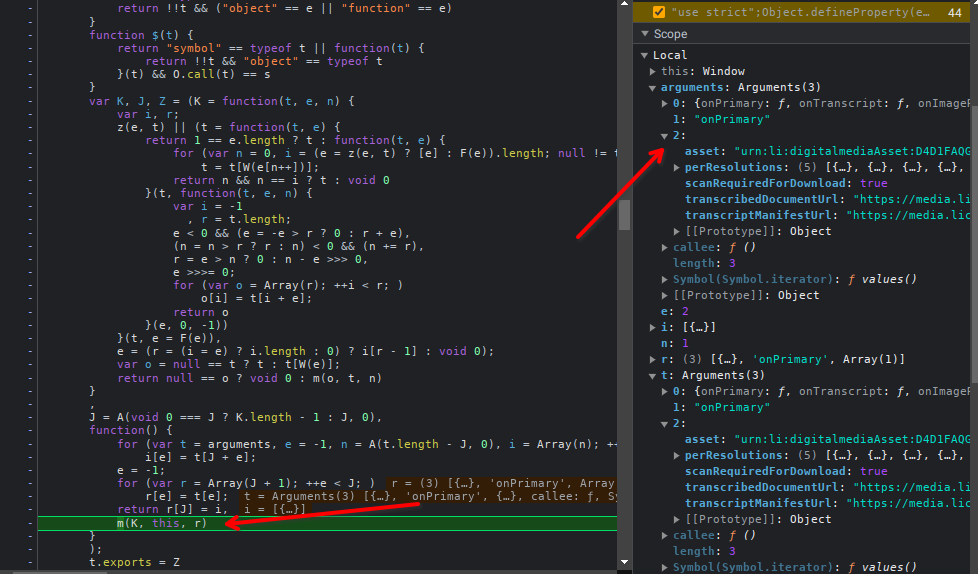
- Stack trace 6
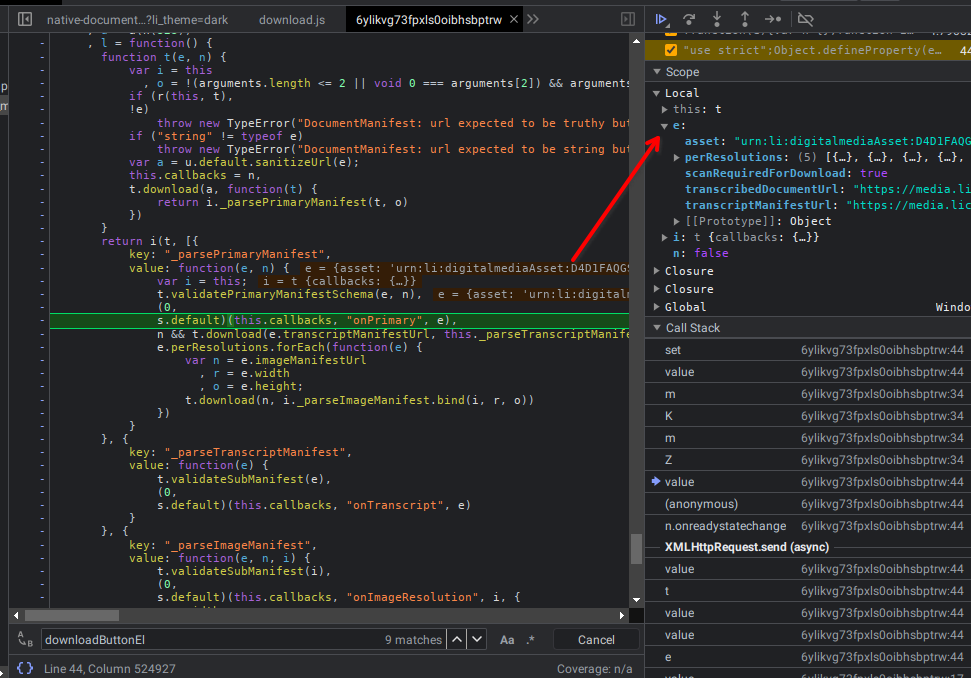
- Stack trace 7
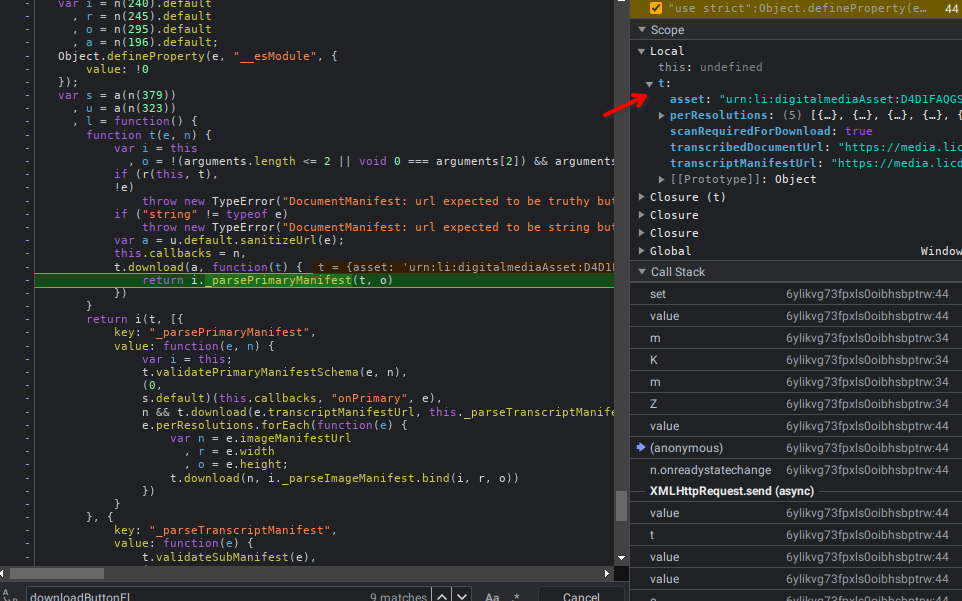
- Stack trace 8
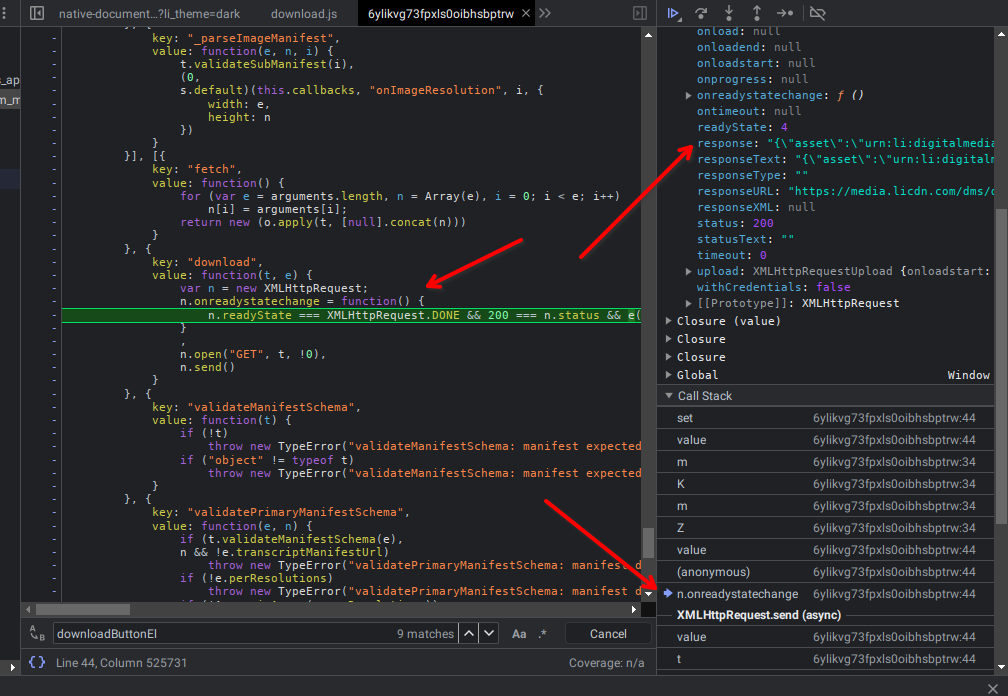
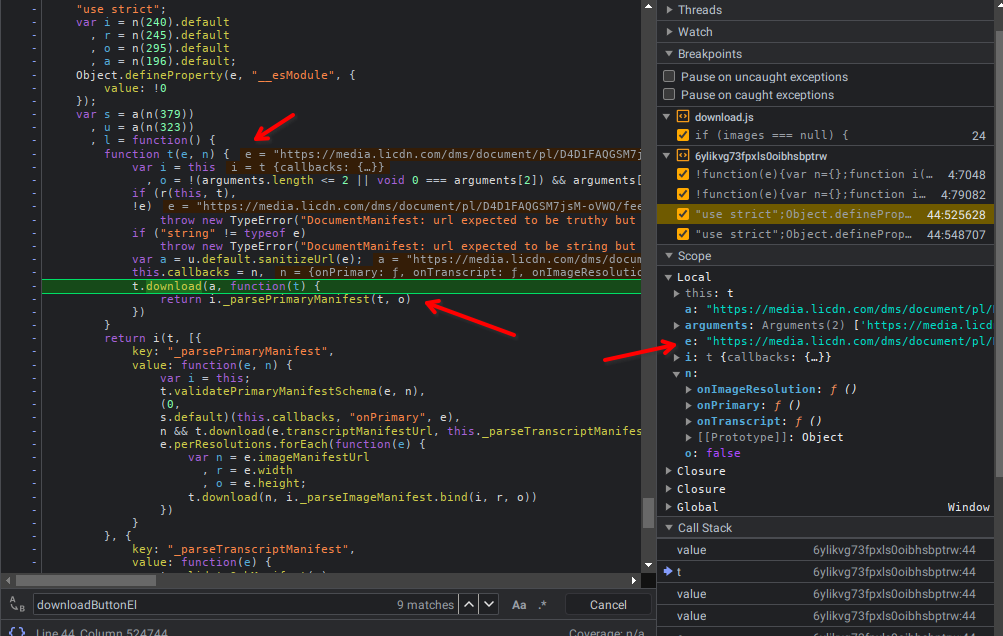
Chegando mais ao final vemos que a url do documento se chama transcribeDocumentUrl, e que a mesma se encontra em um contexto mesmo que a chamada de função parsePrimaryManifest, manisfesto que na função acima da call stack chega por meio de uma requisição ajax, XMLHHttp.
Conteúdo da requisição:
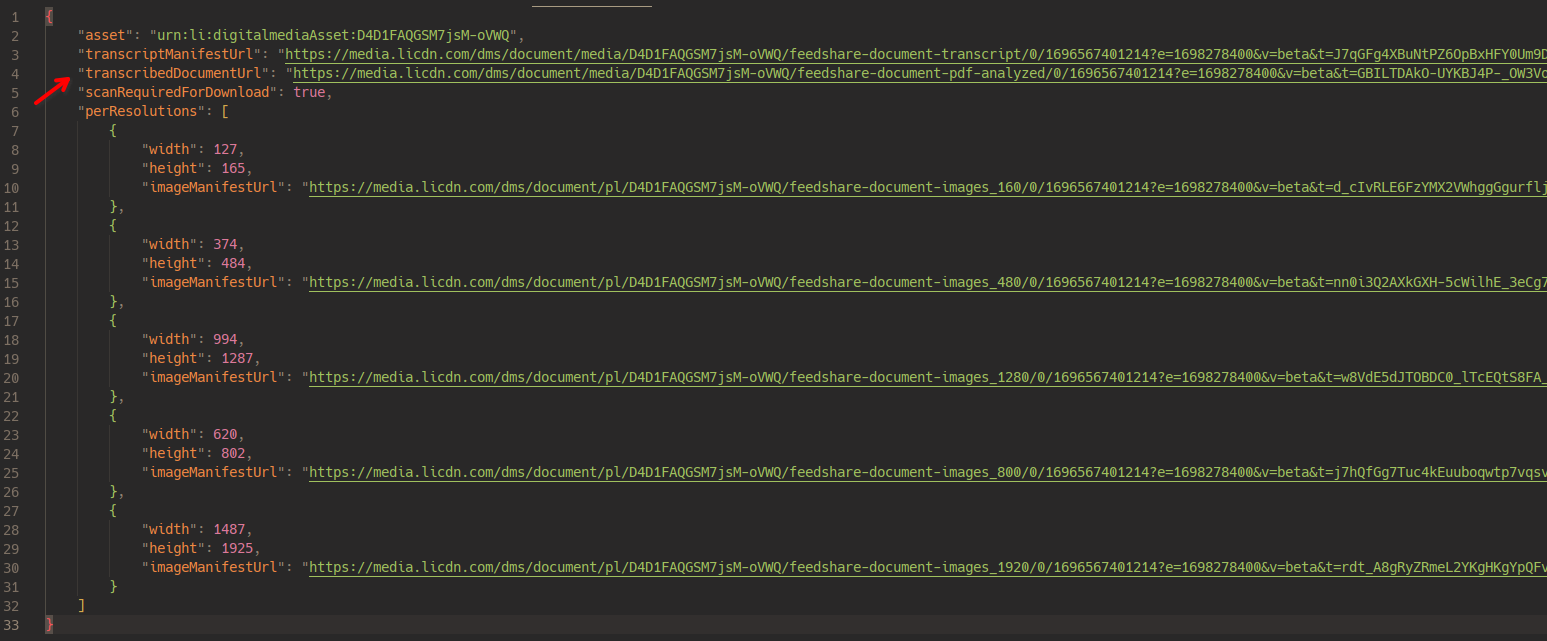
Então as informações da página chegam aqui a partir de um manifesto, que vem por ajax.
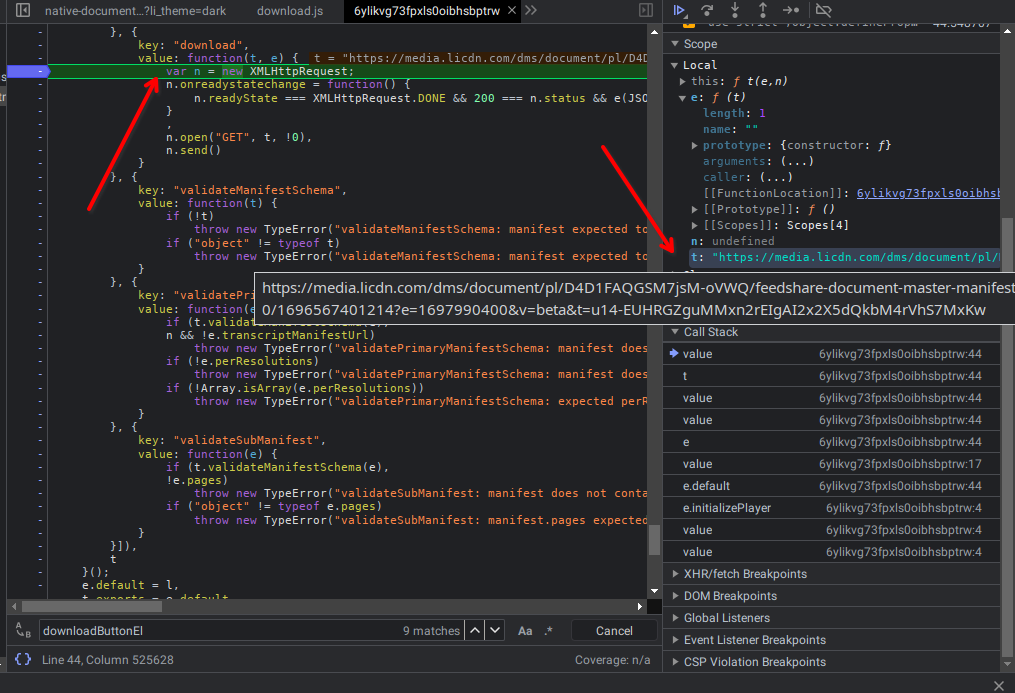
Mas qual a origem? para saber, precisamos ir acima da callstack da chamada ajax para ver de onde vem.
- Ajax manifest stack trace 1
- Ajax manifest stack trace 2
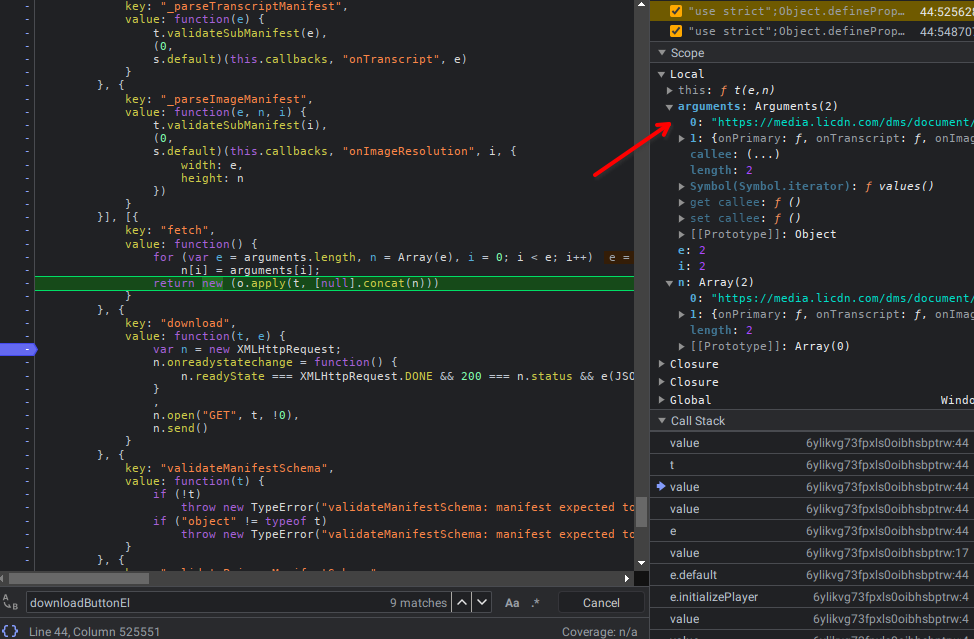
- Ajax manifest stack trace 3

- Ajax manifest stack trace 4

- Ajax manifest stack trace 5

- Ajax manifest stack trace 6

- Ajax manifest stack trace 7

- Ajax manifest stack trace 8
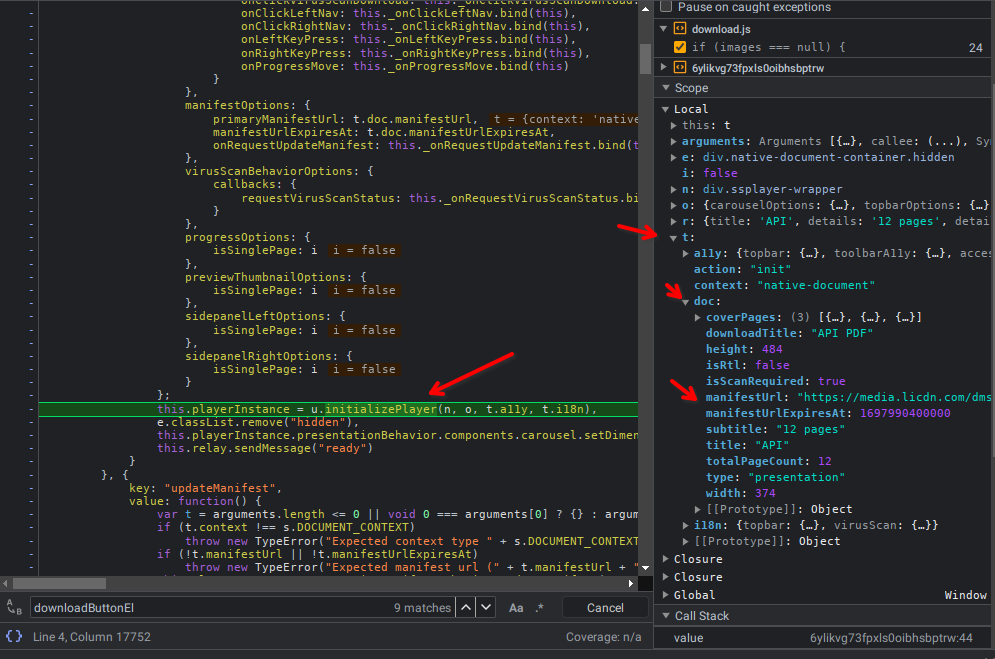
- Ajax manifest stack trace 9

- Ajax manifest stack trace 10

Por fim vemos que a url no manifesto vem de um mapa de key, value onde uma key chama-se _handleMessage, ou seja, isso é uma função de callback utilizada no recebimento de mensagem de window. As funções adjacentes no mapa confirmam isso bem como indicam que isto ṕe um componente esModule compilado para javascript.
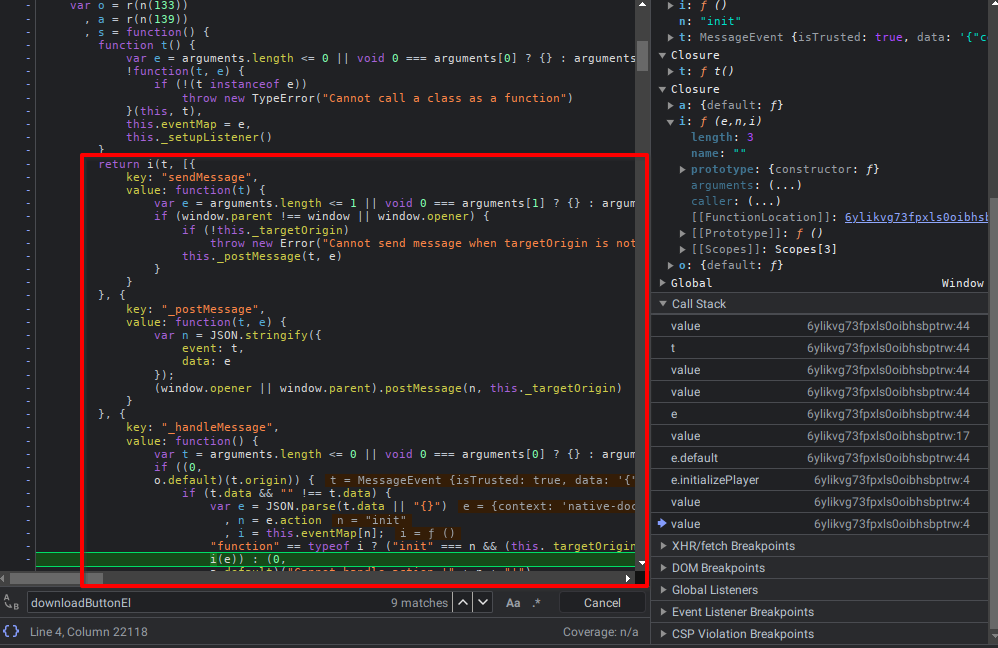
Módulo:

A url do manifesto não vem pura, ela é retirada na função handle message a partir de outro manifesto que presumidamente vem do host, do site do LinkedIn, esse manifesto pai em json se encontra na variavél data na Ajax manifest stack trace 10, e tem a seguinte cara:

Finalmente, estamos quase lá, sabemos que esta informação vem do front, então resolvi pesquisar por parte da url, feedshare-document-master-manifest, no html do LinkedIn mesmo e…. TA DÁ, achamos uma grande tag no html que está HTML enconded:
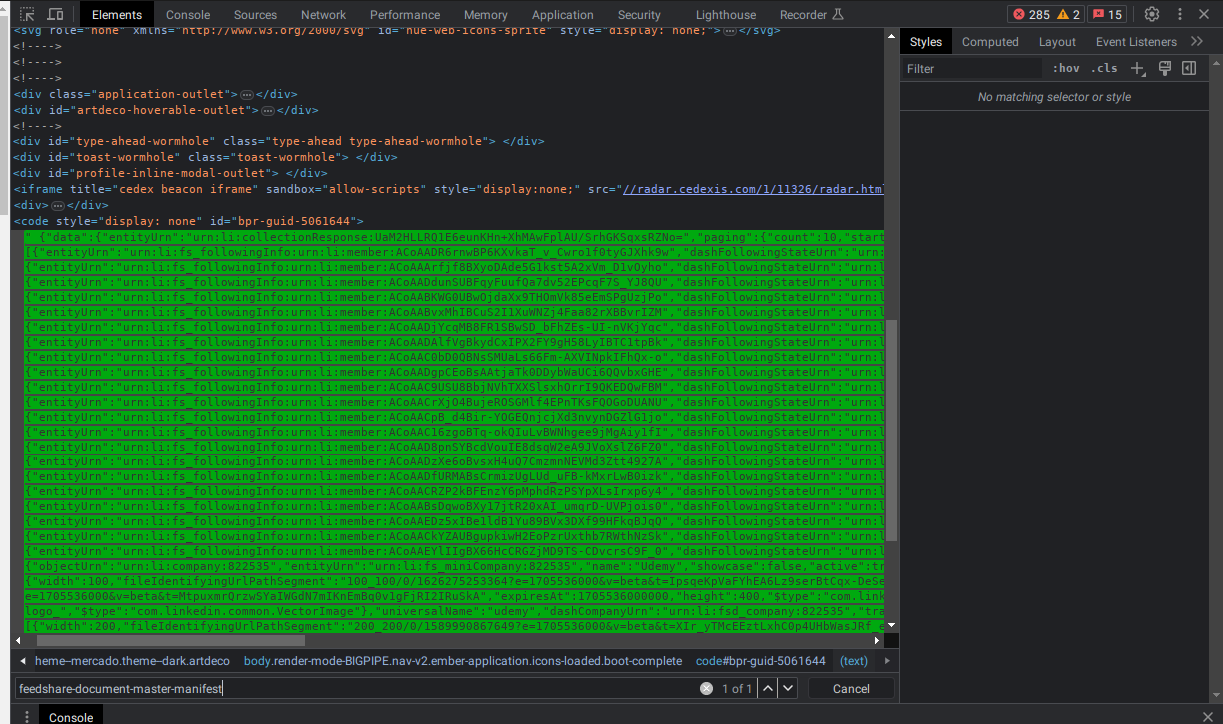
Ao decodificar e formatar o json vemos:

YESSS, temo como retirar agora a fonta principal de todas as informações diretamente fazendo scrapping dos elementos do HTML do LinkedIn.
Finalmente, o pdf
Mas depois de dois dias trabalhados, vemos que a alegria é passageira, lado a lado do manifesto vemos um link também para o documento pdf, sendo diferente do achado anteriormente, mas mesmo assim funcioanl. Desconfio que o encontrado anteriomente passa por um processo externo de checagem de virus, pois vemos várias tags e classes com referências a isso antes e também a própria URL anterior possui analysed na url, enquanto esta não, mas mesmo assim é funcional, então por que não usar.
Pra piorar mais ainda, podemos ver que uma simples busca pelo termo pdf no direciona ao mesmo elemento html 🤦, mas tudo bem, missão cunmprida e com bastante aprendizado!
Assim com o selector a seguir podemos extrair facilmente a url do documento:

Chegando ao fim
Bom, sabendoq ue podemos extrair a URL do pdf diretamente do html, basta generalizar o seletor para achar as informações do manifesto nas tags.
Em extenções chrome precisamos definir um script para ser rodado em um domínio, então vamos colocar as seguintes linahs no manifesto da extensão:
manifest.json:
...
"content_scripts": [
{
"css": ["css/style.css"],
"js": ["scripts/download.js"],
"run_at": "document_idle",
"matches": [
"https://www.linkedin.com/posts/*"
]
}
]
...
E em nosso script vamos definir uma função para criar um botão usando as classes dos botões de midia social originais para obter a mesma estilização.
download.ts:
// generate button
function makeDownloadButton() : HTMLElement{
var div = document.createElement("div");
div.classList.add('feed-shared-social-action-bar__action-button');
var span = document.createElement("span");
div.classList.add('artdeco-hoverable-trigger', 'artdeco-hoverable-trigger--content-placed-top', 'artdeco-hoverable-trigger--is-hoverable', 'ember-view');
var button = document.createElement("button");
button.classList.add(
'social-actions-button',
'artdeco-button',
'artdeco-button--4',
'artdeco-button--tertiary',
'flex-wrap',
'artdeco-button--muted'
);
button.onclick = onDownloadPost;
var svg = document.createElement('img');
svg.width = 24;
svg.height = 24;
svg.classList.add("extensionDownloadIcon");
switch(theme){
case Theme.light:
svg.src = chrome.runtime.getURL("images/downloadLight.svg");
break;
case Theme.dark:
svg.src = chrome.runtime.getURL("images/downloadDark.svg");
break;
}
var text = document.createElement("span");
text.classList.add('artdeco-button__text');
text.textContent = "Download";
div.appendChild(span);
span.appendChild(button);
button.appendChild(svg);
button.appendChild(text);
return div;
}
Temos até deteção de tema lendo a classe da tag html, usado acima para determinar o ícone do botão, o switch case sobre theme.
download.ts:
// theme
var htmlTag = document.querySelector('html');
// global var
var theme : Theme = Theme.light;
if((htmlTag as Element).classList.contains("theme--dark")){
theme = Theme.dark;
}
O callback do botão será:
download.ts:
// Download button callback
function onDownloadPost(ev: MouseEvent) : any{
try {
downloadPost();
} catch (error) {
console.log(error);
}
}
Onde temos a função que identifica os tipos de conteúdo, até o momento somente o tipo de artigo.
download.ts:
// try and get post
function downloadPost(){
var article = document.querySelector('iframe');
if(article){
downloadArticle();
return;
}
}
E finalmente a função de download:
download.ts:
// download article as pdf
function downloadArticle(){
var sources = document.querySelectorAll('code');
var includedData : any;
sources.forEach((code) => {
if(code.id.includes('datalet')) return;
if(!code.textContent) return;
if(!code.textContent.includes('feedshare-document-url-metadata-scrapper-pdf')) return;
includedData = JSON.parse(code.textContent);
});
if(!includedData || !includedData.included)
throw new Error("[ArticlePost]: could not parse document includedData as json");
var doc;
for (let i = 0; i < includedData.included.length; i++) {
var type : string | undefined | null = includedData?.included[i]?.content?.$type;
if(!type) continue;
if(!type.includes('DocumentComponent')) continue;
doc = includedData?.included[i]?.content?.document;
}
if(!doc || !doc.transcribedDocumentUrl || !doc.title)
throw new Error("[ArticlePost]: error trying to read 'document' data in includedData json");
var download : Downloads = {
type: "article",
urls: [{
name: doc.title + '.pdf',
url: doc.transcribedDocumentUrl
}]
};
console.log(`downloading request: ${download}`);
chrome.runtime.sendMessage(download).then((value) => console.log(`downloaded: ${value}`)).catch((err) => console.log(`error downloading: ${err}`));
}
Onde vemos um seletor para todas as tag code, por que são várias dessas e não somente a imediatamente depois do iframe.
Nessa filtramos fora as que tem id que inicia com datalet e procuramos no conteúdo por parte da url do pdf, feedshare-document-url-metadata-scrapper-pdf.
Quando acharmos, fazemos um JSON.parse(), e buscamos nos array includedData.included[] o que contém $type.includes('DocumentComponent').
Desde então acessamos includedData.included[i].content.document.transcribedDocumentUrl e includedData.included[i].content.document.title.
É montado então a estrutura de download e chamada para chrome.runtime.sendMessage() que irá mandar o download para um background worker fazer, o que é necessário pois não conseguimos usar a API do chrome de download dentro desse content-script, sendo que esse só para injetar o botão e pegar as informações.
Registramos nosso worker:
manifest.json:
...
"permissions": [
"background",
"downloads"
],
...
"background": {
"service_worker": "scripts/downloadWorker.js",
"type": "module"
},
...
downloadWorker.ts:
chrome.runtime.onStartup.addListener(() => {
console.log("[Downloader startup!]");
});
chrome.runtime.onInstalled.addListener((details) => {
console.log("[Downloader installed!]");
});
// downloader
chrome.runtime.onMessage.addListener((downloads : Downloads, sender, res) => {
console.log(`downloading receive: ${downloads}`);
switch(downloads.type){
case "article":
downloads.urls.forEach((download) => {
chrome.downloads.download(
{
url: download.url,
method: "GET",
filename: download.name,
conflictAction: "prompt",
saveAs: true
},
(id) => {
console.log(`Downloaded file with id: ${id}`);
}
);
res();
});
break;
default:
case "image":
case "video":
console.log("This extension doesn't download image or video yet!");
break;
}
});
Onde vemos o cadastro de um listener para o event de "message" enviado pelo chrome.runtime.sendMessage() do content-script, que recebe nossa estrutura/classe Downloads, e depois de passar por um switch do tipo, chama a API de downloads do chrome para fazer o download com url e nome recebidos, isso ocasiona naquela janelina de prompt de slavamento de arquivos do chrome, para salvas, salvar como e cancelar.
Extensão publicada
Depois de todo esse rodeio temos finalmente uma extensão funcional, agora quando abrimos posts do linkedin, podemos baixar um artigo como pdf em apenas um clique, sem ter que abrir em tela cheia e clicar em baixa do jeito certo, porém em dois cliques, amazing.
Se quiser usar e acompanhar, você pode baixar a extensão LinkedIn Tools clicando aqui!